Examples of System Design
byte 1 byte -128 to 127.
short 2 bytes -32,768 to 32,767.
int 4 bytes -2,147,483,648 to 2,147,483,647.
long 8 bytes -9,223,372,036,854,775,808 to 9,223,372,036,854,775,807.
Requirement clarification (use cases, post, follow, search, push notification)
API
Estimation (scaling, partitioning, load balancing, caching, storage, network bandwidth)
Data model (SQL schema)
Designing TinyURL
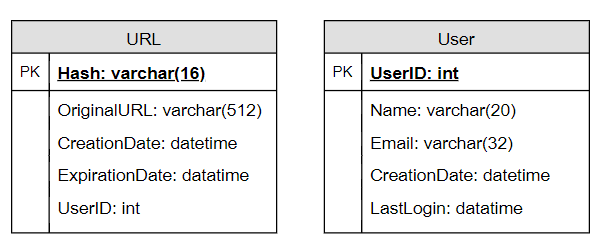
Encoding actual URL
We can compute a unique hash (e.g., MD5 or SHA256, etc.) of the given URL. The hash can then be encoded for displaying. This encoding could be base36 ([a-z ,0-9]) or base62 ([A-Z, a-z, 0-9]) and if we add ‘-’ and ‘.’ we can use base64 encoding. A reasonable question would be, what should be the length of the short key? 6, 8 or 10 characters.
Using base64 encoding, a 6 letter long key would result in 64^6 = ~68.7 billion possible strings
Using base64 encoding, an 8 letter long key would result in 64^8 = ~281 trillion possible strings
With 68.7B unique strings, let’s assume six letter keys would suffice for our system.
If we use the MD5 algorithm as our hash function, it’ll produce a 128-bit hash value. After base64 encoding, we’ll get a string having more than 21 characters (since each base64 character encodes 6 bits of the hash value). Since we only have space for 8 characters per short key, how will we choose our key then? We can take the first 6 (or 8) letters for the key. This could result in key duplication though, upon which we can choose some other characters out of the encoding string or swap some characters.
What are different issues with our solution? We have the following couple of problems with our encoding scheme:
If multiple users enter the same URL, they can get the same shortened URL, which is not acceptable.
What if parts of the URL are URL-encoded? e.g., http://www.educative.io/distributed.php?id=design, and http://www.educative.io/distributed.php%3Fid%3Ddesign are identical except for the URL encoding.
Workaround for the issues: We can append an increasing sequence number to each input URL to make it unique, and then generate a hash of it. We don’t need to store this sequence number in the databases, though. Possible problems with this approach could be an ever-increasing sequence number. Can it overflow? Appending an increasing sequence number will also impact the performance of the service.
Another solution could be to append user id (which should be unique) to the input URL. However, if the user has not signed in, we would have to ask the user to choose a uniqueness key. Even after this, if we have a conflict, we have to keep generating a key until we get a unique one.
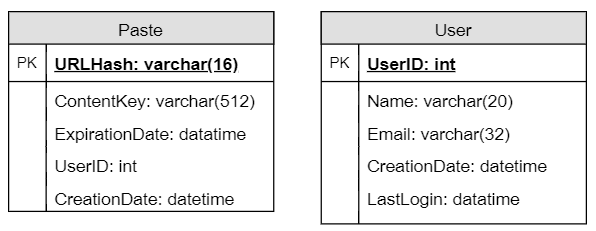
Designing Pastebin
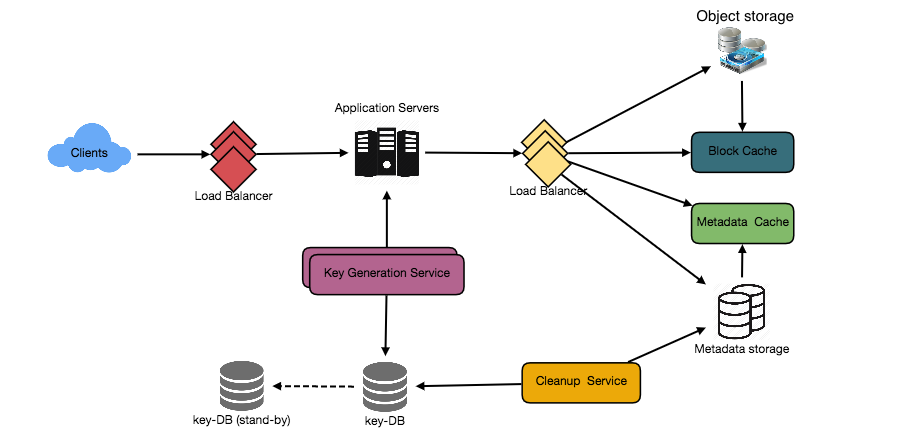
Design Instagram

a. Partitioning based on UserID Let’s assume we shard based on the ‘UserID’ so that we can keep all photos of a user on the same shard. If one DB shard is 1TB, we will need four shards to store 3.7TB of data. Let’s assume for better performance and scalability we keep 10 shards.
So we’ll find the shard number by UserID % 10 and then store the data there. To uniquely identify any photo in our system, we can append shard number with each PhotoID.
How can we generate PhotoIDs? Each DB shard can have its own auto-increment sequence for PhotoIDs and since we will append ShardID with each PhotoID, it will make it unique throughout our system.
What are the different issues with this partitioning scheme?
How would we handle hot users? Several people follow such hot users and a lot of other people see any photo they upload.
Some users will have a lot of photos compared to others, thus making a non-uniform distribution of storage.
What if we cannot store all pictures of a user on one shard? If we distribute photos of a user onto multiple shards will it cause higher latencies?
Storing all photos of a user on one shard can cause issues like unavailability of all of the user’s data if that shard is down or higher latency if it is serving high load etc.
b. Partitioning based on PhotoID If we can generate unique PhotoIDs first and then find a shard number through “PhotoID % 10”, the above problems will have been solved. We would not need to append ShardID with PhotoID in this case as PhotoID will itself be unique throughout the system.
How can we generate PhotoIDs? Here we cannot have an auto-incrementing sequence in each shard to define PhotoID because we need to know PhotoID first to find the shard where it will be stored. One solution could be that we dedicate a separate database instance to generate auto-incrementing IDs. If our PhotoID can fit into 64 bits, we can define a table containing only a 64 bit ID field. So whenever we would like to add a photo in our system, we can insert a new row in this table and take that ID to be our PhotoID of the new photo.
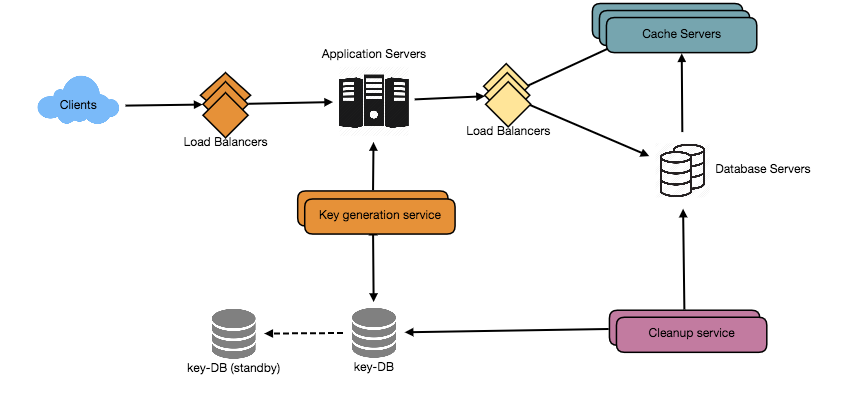
Wouldn’t this key generating DB be a single point of failure? Yes, it would be. A workaround for that could be defining two such databases with one generating even numbered IDs and the other odd numbered. For the MySQL, the following script can define such sequences:
KeyGeneratingServer1:
auto-increment-increment = 2
auto-increment-offset = 1
KeyGeneratingServer2:
auto-increment-increment = 2
auto-increment-offset = 2
We can put a load balancer in front of both of these databases to round robin between them and to deal with downtime. Both these servers could be out of sync with one generating more keys than the other, but this will not cause any issue in our system. We can extend this design by defining separate ID tables for Users, Photo-Comments, or other objects present in our system.
Alternately, we can implement a ‘key’ generation scheme similar to what we have discussed in Designing a URL Shortening service like TinyURL.

Design Dropbox
The metadata Database should be storing information about following objects:
Chunks
Files
User
Devices
Workspace (sync folders)
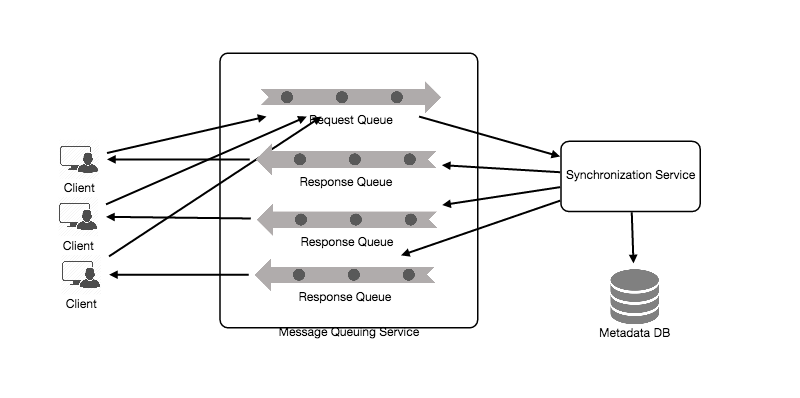
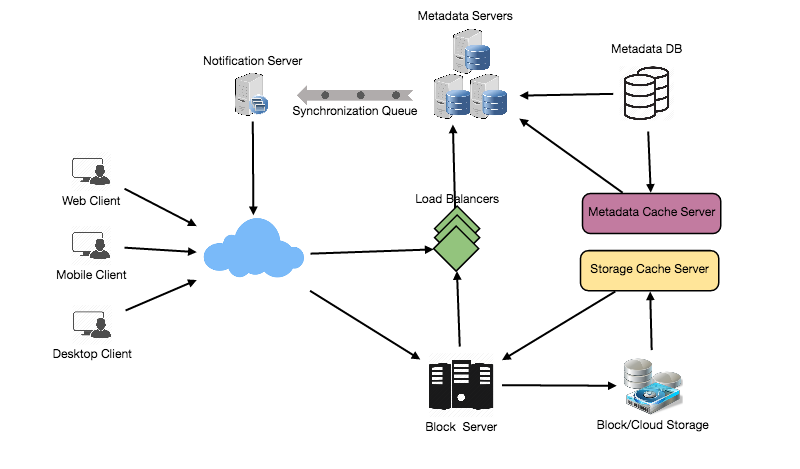
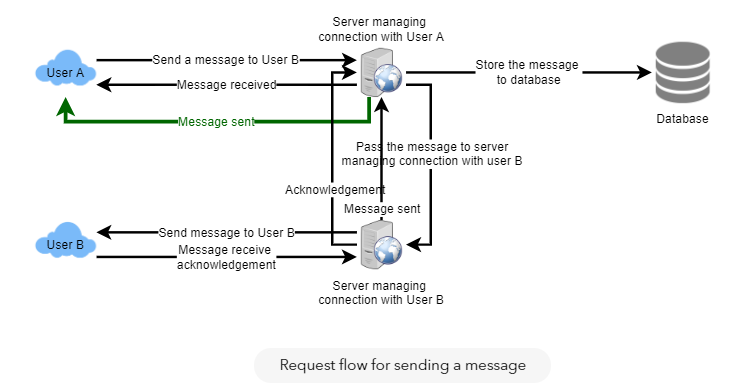
Designing Messenger
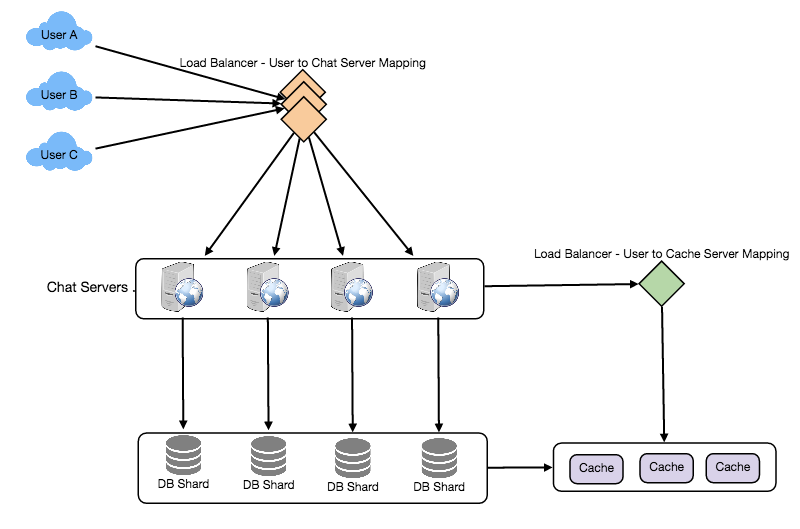
Designing Twitter
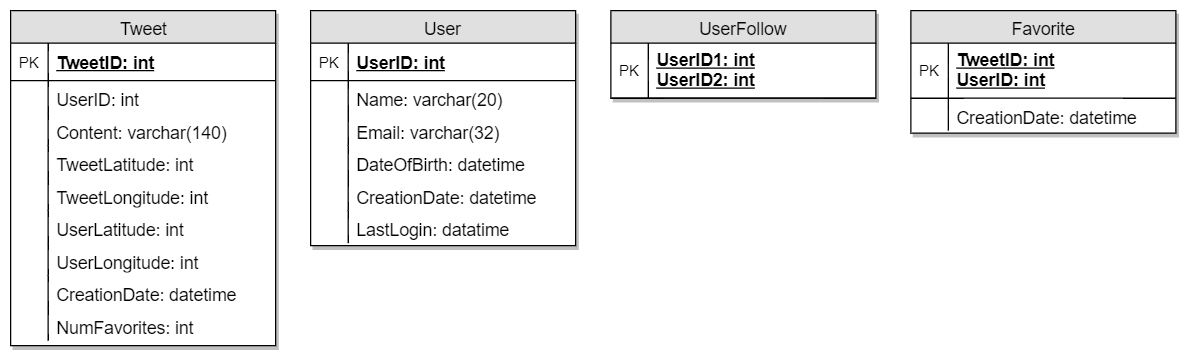
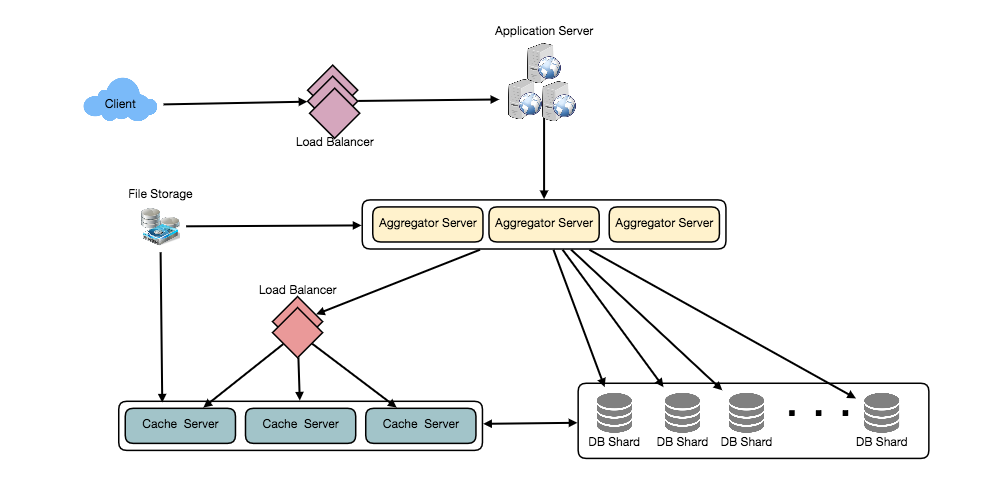
Designing Youtube
At a high-level we would need the following components:
Processing Queue: Each uploaded video will be pushed to a processing queue to be de-queued later for encoding, thumbnail generation, and storage.
Encoder: To encode each uploaded video into multiple formats.
Thumbnails generator: To generate a few thumbnails for each video.
Video and Thumbnail storage: To store video and thumbnail files in some distributed file storage.
User Database: To store user’s information, e.g., name, email, address, etc.
Video metadata storage: A metadata database to store all the information about videos like title, file path in the system, uploading user, total views, likes, dislikes, etc. It will also be used to store all the video comments.
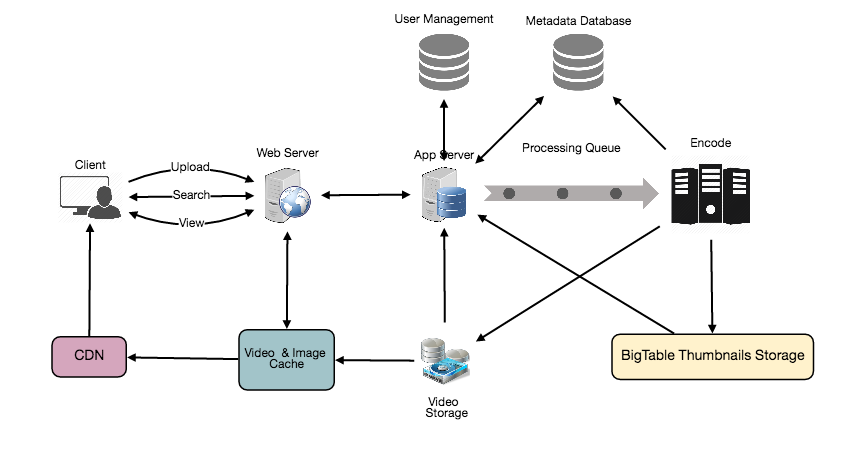
Design Rate Limiter

fixed window

sliding wondow
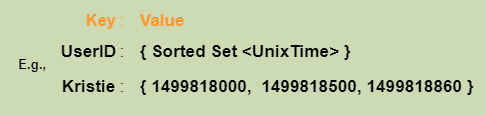
bucket counter
if we have an hourly rate limit we can keep a count for each minute and calculate the sum of all counters in the past hour when we receive a new request to calculate the throttling limit
Design Typeahead Suggestion
Should we have case insensitive trie? For simplicity and search use-case, let’s assume our data is case insensitive.
How to find top suggestion? Now that we can find all the terms for a given prefix, how can we find the top 10 terms for the given prefix? One simple solution could be to store the count of searches that terminated at each node, e.g., if users have searched about ‘CAPTAIN’ 100 times and ‘CAPTION’ 500 times, we can store this number with the last character of the phrase. Now if the user types ‘CAP’ we know the top most searched word under the prefix ‘CAP’ is ‘CAPTION’. So, to find the top suggestions for a given prefix, we can traverse the sub-tree under it.
Given a prefix, how much time will it take to traverse its sub-tree? Given the amount of data we need to index, we should expect a huge tree. Even traversing a sub-tree would take really long, e.g., the phrase ‘system design interview questions’ is 30 levels deep. Since we have very strict latency requirements we do need to improve the efficiency of our solution.
Can we store top suggestions with each node? This can surely speed up our searches but will require a lot of extra storage. We can store top 10 suggestions at each node that we can return to the user. We have to bear the big increase in our storage capacity to achieve the required efficiency.
We can optimize our storage by storing only references of the terminal nodes rather than storing the entire phrase. To find the suggested terms we need to traverse back using the parent reference from the terminal node. We will also need to store the frequency with each reference to keep track of top suggestions.
How would we build this trie? We can efficiently build our trie bottom up. Each parent node will recursively call all the child nodes to calculate their top suggestions and their counts. Parent nodes will combine top suggestions from all of their children to determine their top suggestions.
How to update the trie? Assuming five billion searches every day, which would give us approximately 60K queries per second. If we try to update our trie for every query it’ll be extremely resource intensive and this can hamper our read requests, too. One solution to handle this could be to update our trie offline after a certain interval.
As the new queries come in we can log them and also track their frequencies. Either we can log every query or do sampling and log every 1000th query. For example, if we don’t want to show a term which is searched for less than 1000 times, it’s safe to log every 1000th searched term.
We can have a Map-Reduce (MR) set-up to process all the logging data periodically say every hour. These MR jobs will calculate frequencies of all searched terms in the past hour. We can then update our trie with this new data. We can take the current snapshot of the trie and update it with all the new terms and their frequencies. We should do this offline as we don’t want our read queries to be blocked by update trie requests. We can have two options:
We can make a copy of the trie on each server to update it offline. Once done we can switch to start using it and discard the old one.
Another option is we can have a master-slave configuration for each trie server. We can update slave while the master is serving traffic. Once the update is complete, we can make the slave our new master. We can later update our old master, which can then start serving traffic, too.
How can we update the frequencies of typeahead suggestions? Since we are storing frequencies of our typeahead suggestions with each node, we need to update them too! We can update only differences in frequencies rather than recounting all search terms from scratch. If we’re keeping count of all the terms searched in last 10 days, we’ll need to subtract the counts from the time period no longer included and add the counts for the new time period being included. We can add and subtract frequencies based on Exponential Moving Average (EMA) of each term. In EMA, we give more weight to the latest data. It’s also known as the exponentially weighted moving average.
After inserting a new term in the trie, we’ll go to the terminal node of the phrase and increase its frequency. Since we’re storing the top 10 queries in each node, it is possible that this particular search term jumped into the top 10 queries of a few other nodes. So, we need to update the top 10 queries of those nodes then. We have to traverse back from the node to all the way up to the root. For every parent, we check if the current query is part of the top 10. If so, we update the corresponding frequency. If not, we check if the current query’s frequency is high enough to be a part of the top 10. If so, we insert this new term and remove the term with the lowest frequency.
How can we remove a term from the trie? Let's say we have to remove a term from the trie because of some legal issue or hate or piracy etc. We can completely remove such terms from the trie when the regular update happens, meanwhile, we can add a filtering layer on each server which will remove any such term before sending them to users.
What could be different ranking criteria for suggestions? In addition to a simple count, for terms ranking, we have to consider other factors too, e.g., freshness, user location, language, demographics, personal history etc.
Typeahead Client
We can perform the following optimizations on the client side to improve user’s experience:
The client should only try hitting the server if the user has not pressed any key for 50ms.
If the user is constantly typing, the client can cancel the in-progress requests.
Initially, the client can wait until the user enters a couple of characters.
Clients can pre-fetch some data from the server to save future requests.
Clients can store the recent history of suggestions locally. Recent history has a very high rate of being reused.
Establishing an early connection with the server turns out to be one of the most important factors. As soon as the user opens the search engine website, the client can open a connection with the server. So when a user types in the first character, the client doesn’t waste time in establishing the connection.
The server can push some part of their cache to CDNs and Internet Service Providers (ISPs) for efficiency.
Designing Twitter Search
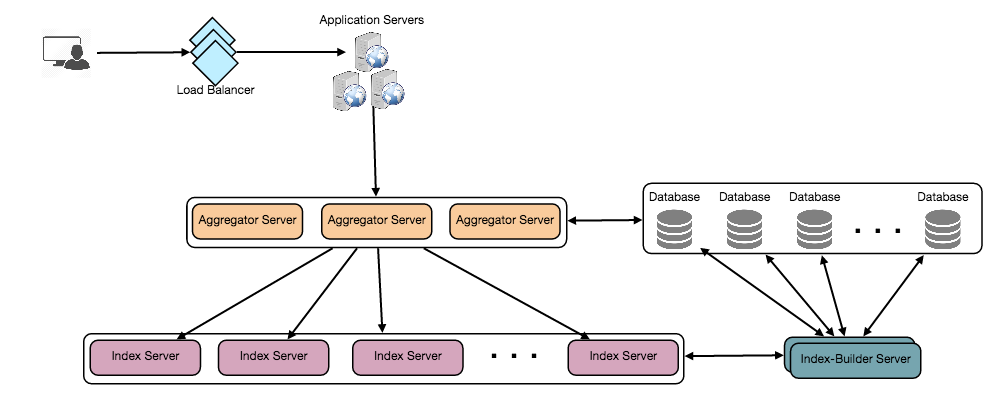
Designing a Web Crawler
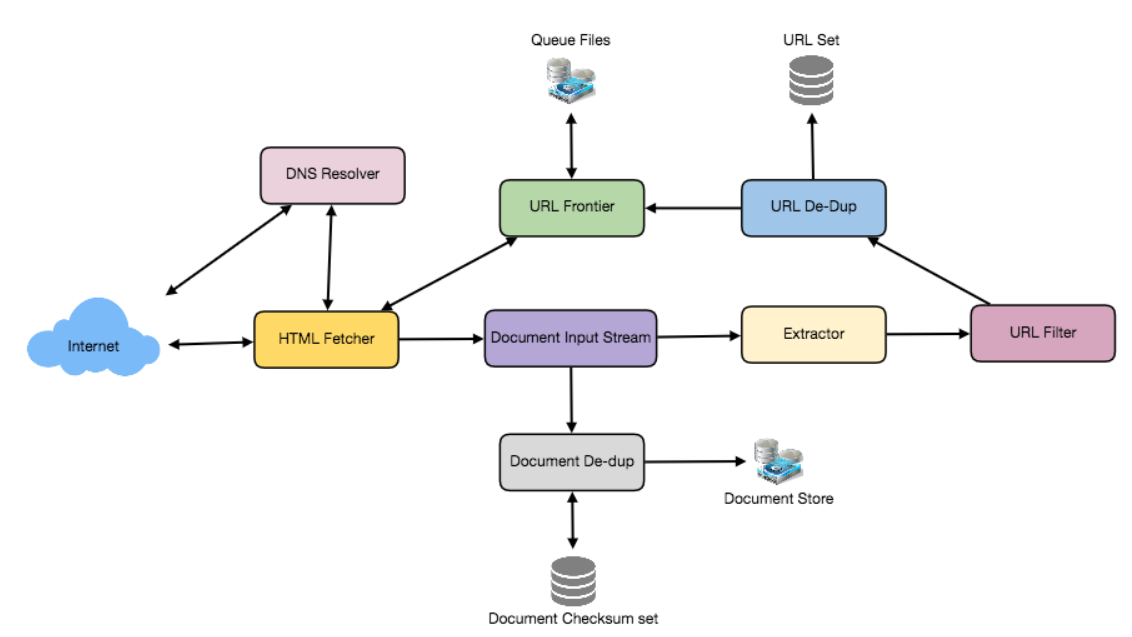
Design news feed
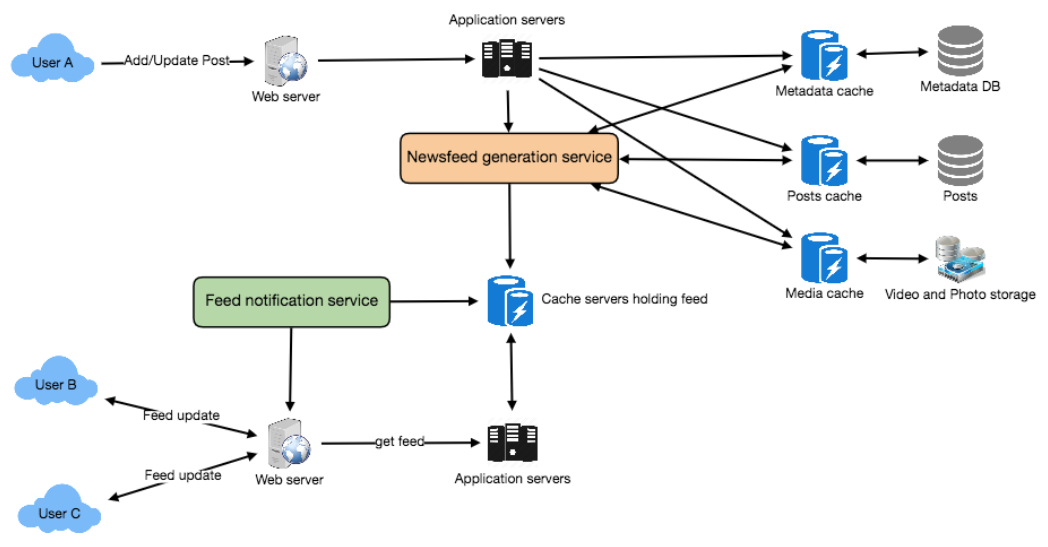
“Pull” model or Fan-out-on-load: This method involves keeping all the recent feed data in memory so that users can pull it from the server whenever they need it. Clients can pull the feed data on a regular basis or manually whenever they need it. Possible problems with this approach are a) New data might not be shown to the users until they issue a pull request, b) It’s hard to find the right pull cadence, as most of the time pull requests will result in an empty response if there is no new data, causing waste of resources.
“Push” model or Fan-out-on-write: For a push system, once a user has published a post, we can immediately push this post to all the followers. The advantage is that when fetching feed you don’t need to go through your friend’s list and get feeds for each of them. It significantly reduces read operations. To efficiently handle this, users have to maintain a Long Poll request with the server for receiving the updates. A possible problem with this approach is that when a user has millions of followers (a celebrity-user) the server has to push updates to a lot of people.
Hybrid: An alternate method to handle feed data could be to use a hybrid approach, i.e., to do a combination of fan-out-on-write and fan-out-on-load. Specifically, we can stop pushing posts from users with a high number of followers (a celebrity user) and only push data for those users who have a few hundred (or thousand) followers. For celebrity users, we can let the followers pull the updates. Since the push operation can be extremely costly for users who have a lot of friends or followers, by disabling fanout for them, we can save a huge number of resources. Another alternate approach could be that, once a user publishes a post, we can limit the fanout to only her online friends. Also, to get benefits from both the approaches, a combination of ‘push to notify’ and ‘pull for serving’ end users is a great way to go. Purely a push or pull model is less versatile.
Should we always notify users if there are new posts available for their newsfeed? It could be useful for users to get notified whenever new data is available. However, on mobile devices, where data usage is relatively expensive, it can consume unnecessary bandwidth. Hence, at least for mobile devices, we can choose not to push data, instead, let users “Pull to Refresh” to get new posts.