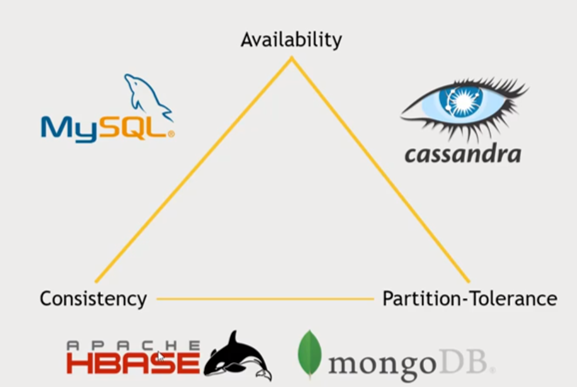
NoSQL vs SQL
RDMBS
Benefit
- SQL
- Joins
- Aggregation
- good for small data volume
- Secondary index
- model data independent of Queries
Drawback
- only scale vertically
- schema not flexible
Normalization - reduce redundency and increase correctness
denormalization - increase performance for read heavy
Cassendra
- table - group of partition
- Partition - collection of rows - unit of access
- PK - partition key (Sharding) + clustering columns (sorting within partition desc)
- Cassandra Collection: Set, List, Map
Good for
- logging events
- IOT
- time series db
- heavy write
Bad for - ad - hoc queries
- joins
Denormalization is a must for cassendra / model queries no joins / one query per table
MongoDB
Embedded and Referenced Relationships
Manual References
{
"_id":ObjectId("52ffc33cd85242f436000001"),
"contact": "987654321",
"dob": "01-01-1991",
"name": "Tom Benzamin",
"address_ids": [
ObjectId("52ffc4a5d85242602e000000"),
ObjectId("52ffc4a5d85242602e000001")
]
}
>var result = db.users.findOne({"name":"Tom Benzamin"},{"address_ids":1})
>var addresses = db.address.find({"_id":{"$in":result["address_ids"]}})
DBRefs
{
"_id":ObjectId("53402597d852426020000002"),
"address": {
"$ref": "address_home",
"$id": ObjectId("534009e4d852427820000002"),
"$db": "tutorialspoint"},
"contact": "987654321",
"dob": "01-01-1991",
"name": "Tom Benzamin"
}
Covered Queries
>db.users.ensureIndex({gender:1,user_name:1})
Covered Query (fetch the required data from indexed data which is very fast. not go looking into database documents.)
>db.users.find({gender:"M"},{user_name:1,_id:0}
Not Covered Query (index does not include _id field)
>db.users.find({gender:"M"},{user_name:1})
Atomic Operations
>db.products.findAndModify({
query:{_id:2,product_available:{$gt:0}},
update:{
$inc:{product_available:-1},
$push:{product_bought_by:{customer:"rob",date:"9-Jan-2014"}}
}
})
Indexing Array Fields and Sub-Document Fields
An ObjectId is a 12-byte BSON type having the following structure −
The first 4 bytes representing the seconds since the unix epoch
The next 3 bytes are the machine identifier
The next 2 bytes consists of process id
The last 3 bytes are a random counter value
Text search
>db.adminCommand({setParameter:true,textSearchEnabled:true})
>db.posts.ensureIndex({post_text:"text"})
>db.posts.find({$text:{$search:"tutorialspoint"}})
Auto-Increment Sequence
>function getNextSequenceValue(sequenceName){
var sequenceDocument = db.counters.findAndModify({
query:{_id: sequenceName },
update: {$inc:{sequence_value:1}},
new:true
});
return sequenceDocument.sequence_value;
}
Mongodb diagnosis and optimization
web service response time < 200ms
mongodb response time < 100ms
long response time
- proper index use explain()
- cacheSizeGB ram size use mongostat()
connection fail - maxIncomingConnections db.serverStatus().connections shows available connections
- ulimit -a -> open files -> max file descriptors
AWS redshift RDS table design optimization
-
Distribution style
Even - The leader node distributes the rows across the slices in a round-robin fashion
Auto - Amazon Redshift assigns an optimal distribution style based on the size of the table data
Key - The leader node places matching values on the same node slice
ALL - replicate table on all nodes -
Sorting Key
define a colum as sort key
CREATE TABLE part (
p_partkey integer not null sortkey distkey,
p_name varchar(22) not null,
p_mfgr varchar(6) not null,
p_category varchar(7) not null,
p_brand1 varchar(9) not null,
p_color varchar(11) not null,
p_type varchar(25) not null,
p_size integer not null,
p_container varchar(10) not null
);
Distribution key and sort key significantly improve query time
Neo4J
// Friend-of-a-friend
(user)-[:KNOWS]-(friend)-[:KNOWS]-(foaf)
// Shortest path
path = shortestPath( (user)-[:KNOWS*..5]-(other) )
// Collaborative filtering
(user)-[:PURCHASED]->(product)<-[:PURCHASED]-()-[:PURCHASED]->(otherProduct)
// Tree navigation
(root)<-[:PARENT*]-(leaf:Category)-[:ITEM]->(data:Product)