AWS Redshift and Apache Airflow pipeline
A reusable production-grade data pipeline that incorporates data quality checks and allows for easy backfills. The source data resides in S3 and needs to be processed in a data warehouse in Amazon Redshift. The source datasets consist of JSON logs that tell about user activity in the application and JSON metadata about the songs the users listen to.
-
Create AWS redshift cluster and test queries.
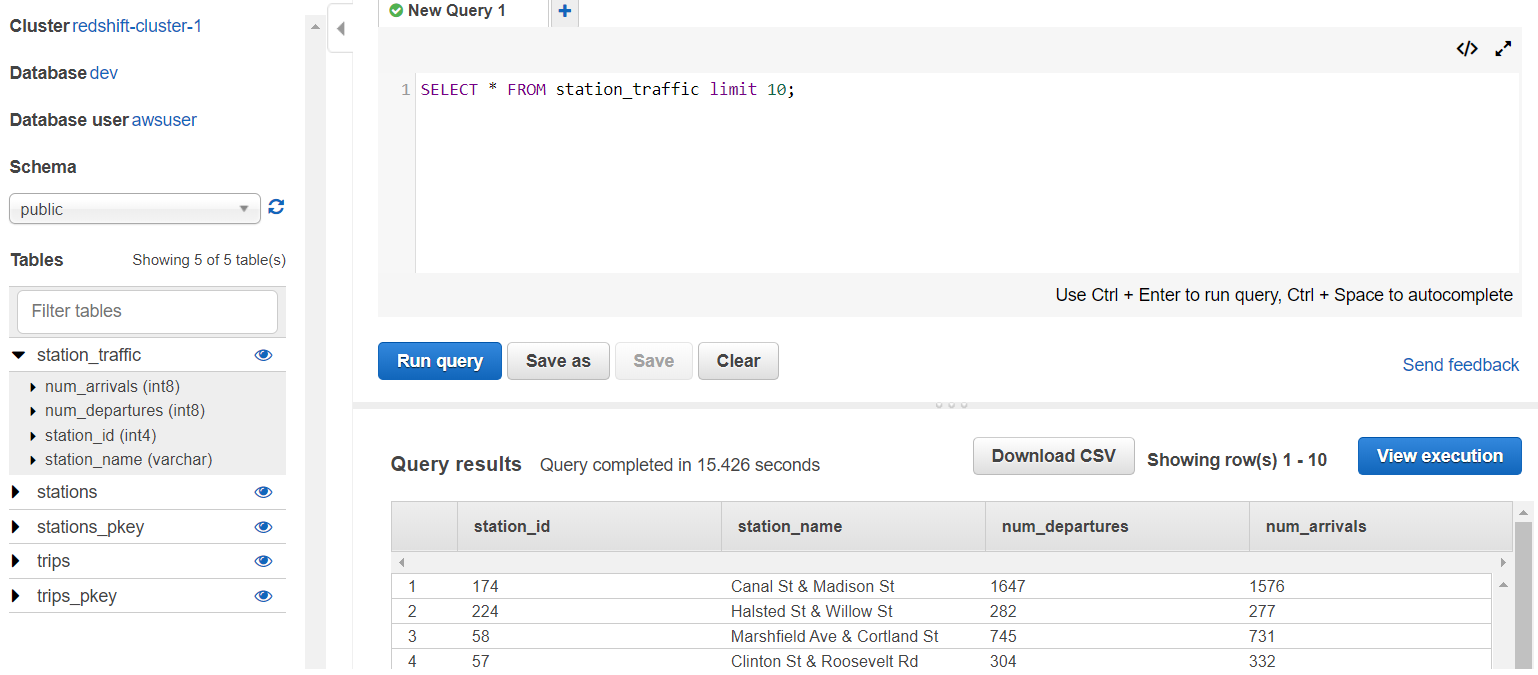
-
Set up AWS S3 hook
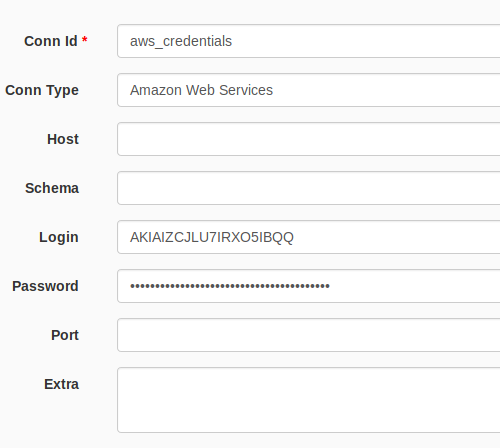
-
Set up redshift connection hook
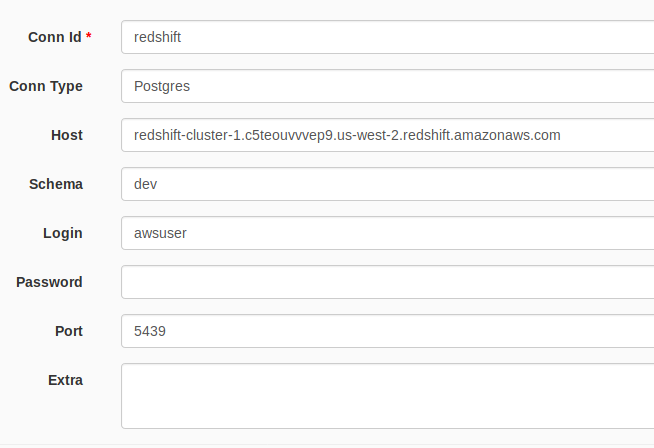
-
Set up Airflow job DAG
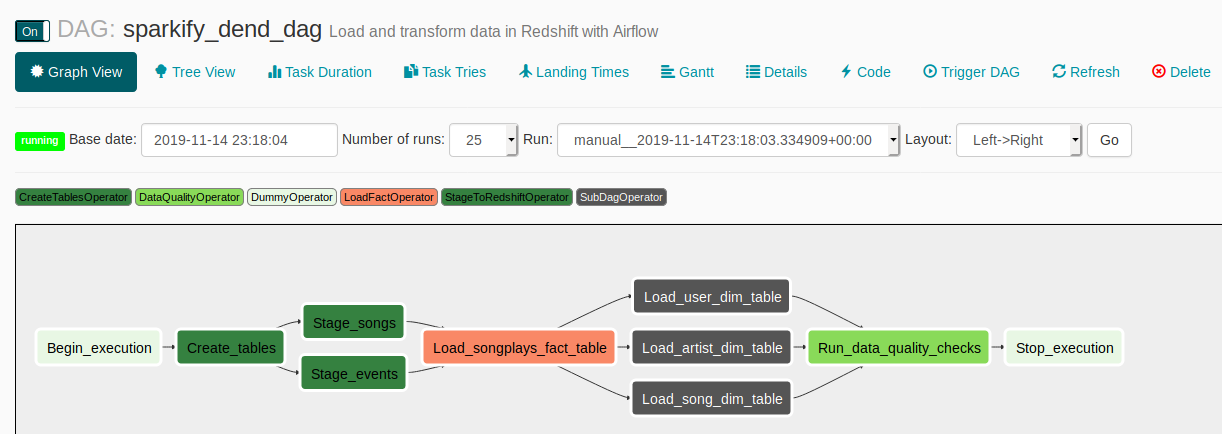
-
Run Airflow scheduler

-
See past job statistics
