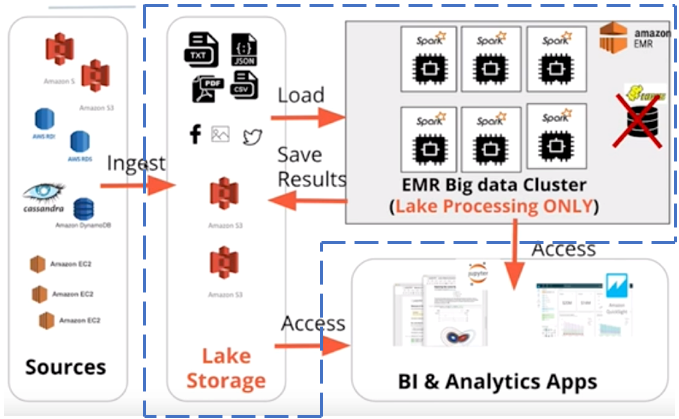
An ETL pipeline that extracts data from S3, processes them using Spark, and loads the data back into S3 as a set of dimensional tables.
Create a Data Lake with Spark and AWS EMR
create a ssh key-pair to securely connect to the EMR cluster
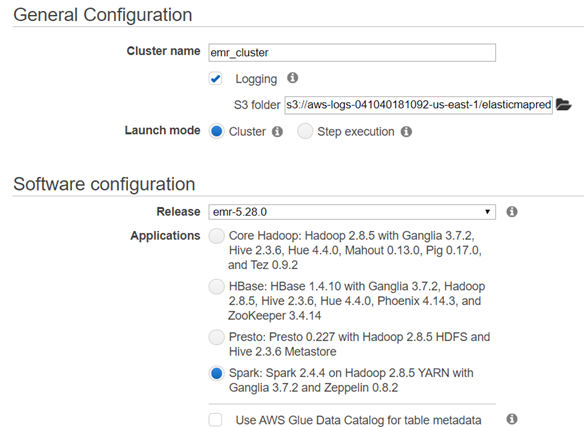
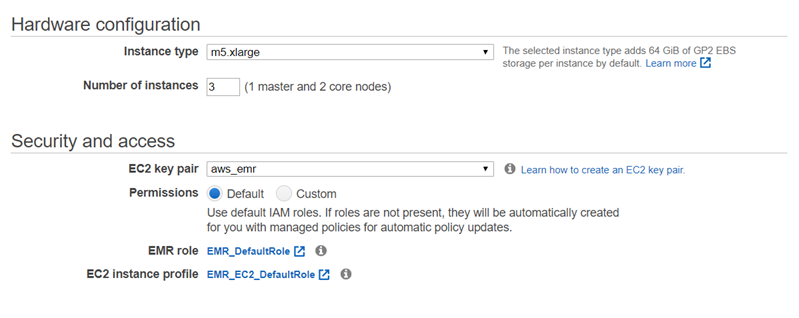
create an EMR cluster
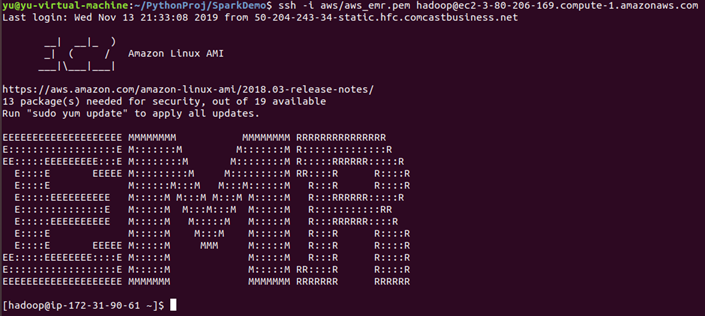
ssh into the master node
access master node jupyter notebook
print("Welcome to my EMR Notebook!")
VBox()
Starting Spark application
ID YARN Application ID Kind State Spark UI Driver log Current session? 1 application_1573680517609_0004 pyspark idle Link Link ✔
FloatProgress(value=0.0, bar_style='info', description='Progress:', layout=Layout(height='25px', width='50%'),…
SparkSession available as 'spark'.
FloatProgress(value=0.0, bar_style='info', description='Progress:', layout=Layout(height='25px', width='50%'),…
Welcome to my EMR Notebook!
%%info
Current session configs: {'conf': {'spark.pyspark.python': 'python3', 'spark.pyspark.virtualenv.enabled': 'true', 'spark.pyspark.virtualenv.type': 'native', 'spark.pyspark.virtualenv.bin.path': '/usr/bin/virtualenv'}, 'kind': 'pyspark'}
ID YARN Application ID Kind State Spark UI Driver log Current session? 1 application_1573680517609_0004 pyspark idle Link Link ✔
sc.list_packages()
VBox()
FloatProgress(value=0.0, bar_style='info', description='Progress:', layout=Layout(height='25px', width='50%'),…
Package Version
-------------------------- -------
beautifulsoup4 4.8.1
boto 2.49.0
jmespath 0.9.4
lxml 4.4.1
mysqlclient 1.4.4
nltk 3.4.5
nose 1.3.4
numpy 1.14.5
pip 19.3.1
py-dateutil 2.2
python36-sagemaker-pyspark 1.2.6
pytz 2019.3
PyYAML 3.11
setuptools 41.6.0
six 1.12.0
soupsieve 1.9.4
wheel 0.33.6
windmill 1.6
sc.install_pypi_package("pandas==0.25.1")
VBox()
FloatProgress(value=0.0, bar_style='info', description='Progress:', layout=Layout(height='25px', width='50%'),…
Collecting pandas==0.25.1
Downloading https://files.pythonhosted.org/packages/73/9b/52e228545d14f14bb2a1622e225f38463c8726645165e1cb7dde95bfe6d4/pandas-0.25.1-cp36-cp36m-manylinux1_x86_64.whl (10.5MB)
Requirement already satisfied: numpy>=1.13.3 in /usr/local/lib64/python3.6/site-packages (from pandas==0.25.1) (1.14.5)
Collecting python-dateutil>=2.6.1
Downloading https://files.pythonhosted.org/packages/d4/70/d60450c3dd48ef87586924207ae8907090de0b306af2bce5d134d78615cb/python_dateutil-2.8.1-py2.py3-none-any.whl (227kB)
Requirement already satisfied: pytz>=2017.2 in /usr/local/lib/python3.6/site-packages (from pandas==0.25.1) (2019.3)
Requirement already satisfied: six>=1.5 in /usr/local/lib/python3.6/site-packages (from python-dateutil>=2.6.1->pandas==0.25.1) (1.12.0)
Installing collected packages: python-dateutil, pandas
Successfully installed pandas-0.25.1 python-dateutil-2.8.1
sc.install_pypi_package("matplotlib", "https://pypi.org/simple") #Install matplotlib from given PyPI repository
VBox()
FloatProgress(value=0.0, bar_style='info', description='Progress:', layout=Layout(height='25px', width='50%'),…
Collecting matplotlib
Downloading https://files.pythonhosted.org/packages/57/4f/dd381ecf6c6ab9bcdaa8ea912e866dedc6e696756156d8ecc087e20817e2/matplotlib-3.1.1-cp36-cp36m-manylinux1_x86_64.whl (13.1MB)
Requirement already satisfied: numpy>=1.11 in /usr/local/lib64/python3.6/site-packages (from matplotlib) (1.14.5)
Collecting kiwisolver>=1.0.1
Downloading https://files.pythonhosted.org/packages/f8/a1/5742b56282449b1c0968197f63eae486eca2c35dcd334bab75ad524e0de1/kiwisolver-1.1.0-cp36-cp36m-manylinux1_x86_64.whl (90kB)
Requirement already satisfied: python-dateutil>=2.1 in /mnt/tmp/1573683191129-0/lib/python3.6/site-packages (from matplotlib) (2.8.1)
Collecting pyparsing!=2.0.4,!=2.1.2,!=2.1.6,>=2.0.1
Downloading https://files.pythonhosted.org/packages/c0/0c/fc2e007d9a992d997f04a80125b0f183da7fb554f1de701bbb70a8e7d479/pyparsing-2.4.5-py2.py3-none-any.whl (67kB)
Collecting cycler>=0.10
Downloading https://files.pythonhosted.org/packages/f7/d2/e07d3ebb2bd7af696440ce7e754c59dd546ffe1bbe732c8ab68b9c834e61/cycler-0.10.0-py2.py3-none-any.whl
Requirement already satisfied: setuptools in /mnt/tmp/1573683191129-0/lib/python3.6/site-packages (from kiwisolver>=1.0.1->matplotlib) (41.6.0)
Requirement already satisfied: six>=1.5 in /usr/local/lib/python3.6/site-packages (from python-dateutil>=2.1->matplotlib) (1.12.0)
Installing collected packages: kiwisolver, pyparsing, cycler, matplotlib
Successfully installed cycler-0.10.0 kiwisolver-1.1.0 matplotlib-3.1.1 pyparsing-2.4.5
sc.list_packages()
VBox()
FloatProgress(value=0.0, bar_style='info', description='Progress:', layout=Layout(height='25px', width='50%'),…
Package Version
-------------------------- -------
beautifulsoup4 4.8.1
boto 2.49.0
cycler 0.10.0
jmespath 0.9.4
kiwisolver 1.1.0
lxml 4.4.1
matplotlib 3.1.1
mysqlclient 1.4.4
nltk 3.4.5
nose 1.3.4
numpy 1.14.5
pandas 0.25.1
pip 19.3.1
py-dateutil 2.2
pyparsing 2.4.5
python-dateutil 2.8.1
python36-sagemaker-pyspark 1.2.6
pytz 2019.3
PyYAML 3.11
setuptools 41.6.0
six 1.12.0
soupsieve 1.9.4
wheel 0.33.6
windmill 1.6
df = spark.read.parquet('s3://amazon-reviews-pds/parquet/product_category=Books/*.parquet')
VBox()
FloatProgress(value=0.0, bar_style='info', description='Progress:', layout=Layout(height='25px', width='50%'),…
df.printSchema()
num_of_books = df.select('product_id').distinct().count()
print(f'Number of Books: {num_of_books:,}')
VBox()
FloatProgress(value=0.0, bar_style='info', description='Progress:', layout=Layout(height='25px', width='50%'),…
root
|-- marketplace: string (nullable = true)
|-- customer_id: string (nullable = true)
|-- review_id: string (nullable = true)
|-- product_id: string (nullable = true)
|-- product_parent: string (nullable = true)
|-- product_title: string (nullable = true)
|-- star_rating: integer (nullable = true)
|-- helpful_votes: integer (nullable = true)
|-- total_votes: integer (nullable = true)
|-- vine: string (nullable = true)
|-- verified_purchase: string (nullable = true)
|-- review_headline: string (nullable = true)
|-- review_body: string (nullable = true)
|-- review_date: date (nullable = true)
|-- year: integer (nullable = true)
Number of Books: 3,423,743
install python libraries
sudo easy_install-3.6 pip
sudo /usr/local/bin/pip3 install paramiko nltk scipy scikit-learn pandas
upload file to EMR
spark-submit job
import configparser
from datetime import datetime
import os
from pyspark.sql import SparkSession
from pyspark.sql.functions import udf, col
from pyspark.sql.functions import year, month, dayofmonth, hour, weekofyear, date_format
from pyspark.sql import functions as F
from pyspark.sql import types as T
import pandas as pd
pd.set_option('display.max_columns', 500)
config = configparser.ConfigParser()
#Normally this file should be in ~/.aws/credentials
config.read_file(open('dl.cfg'))
os.environ["AWS_ACCESS_KEY_ID"]= config['AWS']['AWS_ACCESS_KEY_ID']
os.environ["AWS_SECRET_ACCESS_KEY"]= config['AWS']['AWS_SECRET_ACCESS_KEY']
def create_spark_session():
spark = SparkSession \
.builder \
.config("spark.jars.packages", "org.apache.hadoop:hadoop-aws:2.7.0") \
.getOrCreate()
return spark
# create the spark session
spark = create_spark_session()
# read data from my S3 bucket. This is the same data in workspace
songPath = 's3a://testemrs3/song_data/*/*/*/*.json'
logPath = 's3a://testemrs3/log_data/*.json'
# define output paths
output = 's3a://testemrs3/schema/'
process song data
create song_table
# Step 1: Read in the song data
df_song = spark.read.json(songPath)
# check the schema
df_song.printSchema()
root
|-- artist_id: string (nullable = true)
|-- artist_latitude: double (nullable = true)
|-- artist_location: string (nullable = true)
|-- artist_longitude: double (nullable = true)
|-- artist_name: string (nullable = true)
|-- duration: double (nullable = true)
|-- num_songs: long (nullable = true)
|-- song_id: string (nullable = true)
|-- title: string (nullable = true)
|-- year: long (nullable = true)
# Step 2: extract columns to create songs table
song_cols = ['song_id', 'title', 'artist_id', 'year', 'duration']
# groupby song_id and select the first record's title in the group.
t1 = df_song.select(F.col('song_id'), 'title') \
.groupBy('song_id') \
.agg({'title': 'first'}) \
.withColumnRenamed('first(title)', 'title1')
t2 = df_song.select(song_cols)
t1.toPandas().head()
song_id
title1
0
SOGOSOV12AF72A285E
¿Dónde va Chichi?
1
SOMZWCG12A8C13C480
I Didn't Mean To
2
SOUPIRU12A6D4FA1E1
Der Kleine Dompfaff
3
SOXVLOJ12AB0189215
Amor De Cabaret
4
SOWTBJW12AC468AC6E
Broken-Down Merry-Go-Round
t2.toPandas().head()
song_id
title
artist_id
year
duration
0
SOBAYLL12A8C138AF9
Sono andati? Fingevo di dormire
ARDR4AC1187FB371A1
0
511.16363
1
SOOLYAZ12A6701F4A6
Laws Patrolling (Album Version)
AREBBGV1187FB523D2
0
173.66159
2
SOBBUGU12A8C13E95D
Setting Fire to Sleeping Giants
ARMAC4T1187FB3FA4C
2004
207.77751
3
SOAOIBZ12AB01815BE
I Hold Your Hand In Mine [Live At Royal Albert...
ARPBNLO1187FB3D52F
2000
43.36281
4
SONYPOM12A8C13B2D7
I Think My Wife Is Running Around On Me (Taco ...
ARDNS031187B9924F0
2005
186.48771
song_table_df = t1.join(t2, 'song_id') \
.where(F.col("title1") == F.col("title")) \
.select(song_cols)
song_table_df.toPandas().head()
song_id
title
artist_id
year
duration
0
SOBAYLL12A8C138AF9
Sono andati? Fingevo di dormire
ARDR4AC1187FB371A1
0
511.16363
1
SOOLYAZ12A6701F4A6
Laws Patrolling (Album Version)
AREBBGV1187FB523D2
0
173.66159
2
SOBBUGU12A8C13E95D
Setting Fire to Sleeping Giants
ARMAC4T1187FB3FA4C
2004
207.77751
3
SOAOIBZ12AB01815BE
I Hold Your Hand In Mine [Live At Royal Albert...
ARPBNLO1187FB3D52F
2000
43.36281
4
SONYPOM12A8C13B2D7
I Think My Wife Is Running Around On Me (Taco ...
ARDNS031187B9924F0
2005
186.48771
song_table_df.toPandas().shape
(71, 5)
df_song.toPandas().shape
(71, 10)
# Step 3: Write this to a parquet file
song_table_df.write.parquet('data/songs_table', partitionBy=['year', 'artist_id'], mode='Overwrite')
# write this to s3 bucket
song_table_df.write.parquet(output + 'songs_table', partitionBy=['year', 'artist_id'], mode='Overwrite')
create artists_table
# define the cols
artists_cols = ["artist_id", "artist_name", "artist_location", "artist_latitude", "artist_longitude"]
df_song.printSchema()
root
|-- artist_id: string (nullable = true)
|-- artist_latitude: double (nullable = true)
|-- artist_location: string (nullable = true)
|-- artist_longitude: double (nullable = true)
|-- artist_name: string (nullable = true)
|-- duration: double (nullable = true)
|-- num_songs: long (nullable = true)
|-- song_id: string (nullable = true)
|-- title: string (nullable = true)
|-- year: long (nullable = true)
# groupby song_id and select the first record's title in the group.
t1 = df_song.select(F.col('artist_id'), 'artist_name') \
.groupBy('artist_id') \
.agg({'artist_name': 'first'}) \
.withColumnRenamed('first(artist_name)', 'artist_name1')
t2 = df_song.select(artists_cols)
t1.toPandas().head()
artist_id
artist_name1
0
AR9AWNF1187B9AB0B4
Kenny G featuring Daryl Hall
1
AR0IAWL1187B9A96D0
Danilo Perez
2
AR0RCMP1187FB3F427
Billie Jo Spears
3
AREDL271187FB40F44
Soul Mekanik
4
ARI3BMM1187FB4255E
Alice Stuart
t2.toPandas().head()
artist_id
artist_name
artist_location
artist_latitude
artist_longitude
0
ARDR4AC1187FB371A1
Montserrat Caballé;Placido Domingo;Vicente Sar...
NaN
NaN
1
AREBBGV1187FB523D2
Mike Jones (Featuring CJ_ Mello & Lil' Bran)
Houston, TX
NaN
NaN
2
ARMAC4T1187FB3FA4C
The Dillinger Escape Plan
Morris Plains, NJ
40.82624
-74.47995
3
ARPBNLO1187FB3D52F
Tiny Tim
New York, NY
40.71455
-74.00712
4
ARDNS031187B9924F0
Tim Wilson
Georgia
32.67828
-83.22295
artists_table_df = t1.join(t2, 'artist_id') \
.where(F.col("artist_name1") == F.col("artist_name")) \
.select(artists_cols)
artists_table_df.toPandas().head()
artist_id
artist_name
artist_location
artist_latitude
artist_longitude
0
ARDR4AC1187FB371A1
Montserrat Caballé;Placido Domingo;Vicente Sar...
NaN
NaN
1
AREBBGV1187FB523D2
Mike Jones (Featuring CJ_ Mello & Lil' Bran)
Houston, TX
NaN
NaN
2
ARMAC4T1187FB3FA4C
The Dillinger Escape Plan
Morris Plains, NJ
40.82624
-74.47995
3
ARPBNLO1187FB3D52F
Tiny Tim
New York, NY
40.71455
-74.00712
4
ARDNS031187B9924F0
Tim Wilson
Georgia
32.67828
-83.22295
# write this to s3 bucket
artists_table_df.write.parquet(output + 'artists_table', mode='Overwrite')
artists_table_df.write.parquet('data/artists_table', mode='Overwrite')
# read the partitioned data
df_artists_read = spark.read.option("mergeSchema", "true").parquet("data/artists_table")
Process log data
# Step 1: Read in the log data
df_log = spark.read.json(logPath)
df_log.printSchema()
root
|-- artist: string (nullable = true)
|-- auth: string (nullable = true)
|-- firstName: string (nullable = true)
|-- gender: string (nullable = true)
|-- itemInSession: long (nullable = true)
|-- lastName: string (nullable = true)
|-- length: double (nullable = true)
|-- level: string (nullable = true)
|-- location: string (nullable = true)
|-- method: string (nullable = true)
|-- page: string (nullable = true)
|-- registration: double (nullable = true)
|-- sessionId: long (nullable = true)
|-- song: string (nullable = true)
|-- status: long (nullable = true)
|-- ts: long (nullable = true)
|-- userAgent: string (nullable = true)
|-- userId: string (nullable = true)
df_log.filter(F.col("page") == "NextSong").toPandas().head()
artist
auth
firstName
gender
itemInSession
lastName
length
level
location
method
page
registration
sessionId
song
status
ts
userAgent
userId
0
Harmonia
Logged In
Ryan
M
0
Smith
655.77751
free
San Jose-Sunnyvale-Santa Clara, CA
PUT
NextSong
1.541017e+12
583
Sehr kosmisch
200
1542241826796
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/5...
26
1
The Prodigy
Logged In
Ryan
M
1
Smith
260.07465
free
San Jose-Sunnyvale-Santa Clara, CA
PUT
NextSong
1.541017e+12
583
The Big Gundown
200
1542242481796
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/5...
26
2
Train
Logged In
Ryan
M
2
Smith
205.45261
free
San Jose-Sunnyvale-Santa Clara, CA
PUT
NextSong
1.541017e+12
583
Marry Me
200
1542242741796
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/5...
26
3
Sony Wonder
Logged In
Samuel
M
0
Gonzalez
218.06975
free
Houston-The Woodlands-Sugar Land, TX
PUT
NextSong
1.540493e+12
597
Blackbird
200
1542253449796
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_4...
61
4
Van Halen
Logged In
Tegan
F
2
Levine
289.38404
paid
Portland-South Portland, ME
PUT
NextSong
1.540794e+12
602
Best Of Both Worlds (Remastered Album Version)
200
1542260935796
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_4...
80
# Step 2: filter by actions for song plays
df_log = df_log.filter(F.col("page") == "NextSong")
df_log.toPandas().shape
(6820, 18)
# Step 3: extract columns for users table
users_cols = ["userId", "firstName", "lastName", "gender", "level"]
df_log.select(users_cols).toPandas().head()
userId
firstName
lastName
gender
level
0
26
Ryan
Smith
M
free
1
26
Ryan
Smith
M
free
2
26
Ryan
Smith
M
free
3
61
Samuel
Gonzalez
M
free
4
80
Tegan
Levine
F
paid
df_log.select(users_cols).toPandas().shape
(6820, 5)
df_log.select(users_cols).dropDuplicates().toPandas().shape
(104, 5)
df_log.select(users_cols).dropDuplicates().toPandas().head()
userId
firstName
lastName
gender
level
0
57
Katherine
Gay
F
free
1
84
Shakira
Hunt
F
free
2
22
Sean
Wilson
F
free
3
52
Theodore
Smith
M
free
4
80
Tegan
Levine
F
paid
users_table_df = df_log.select(users_cols).dropDuplicates()
# write this to s3 bucket
users_table_df.write.parquet(output + 'users_table', mode='Overwrite')
users_table_df.write.parquet('data/users_table', mode='Overwrite')
Time table
# # create timestamp column from original timestamp column
get_timestamp = udf()
df_log.select('ts').toPandas().head()
ts
0
1542241826796
1
1542242481796
2
1542242741796
3
1542253449796
4
1542260935796
df.withColumn('epoch', f.date_format(df.epoch.cast(dataType=t.TimestampType()), "yyyy-MM-dd"))
df_log.withColumn('ts', F.date_format(df_log.ts.cast(dataType=T.TimestampType()), "yyyy-MM-dd")).toPandas().head()
artist
auth
firstName
gender
itemInSession
lastName
length
level
location
method
page
registration
sessionId
song
status
ts
userAgent
userId
0
Harmonia
Logged In
Ryan
M
0
Smith
655.77751
free
San Jose-Sunnyvale-Santa Clara, CA
PUT
NextSong
1.541017e+12
583
Sehr kosmisch
200
50841-09-12
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/5...
26
1
The Prodigy
Logged In
Ryan
M
1
Smith
260.07465
free
San Jose-Sunnyvale-Santa Clara, CA
PUT
NextSong
1.541017e+12
583
The Big Gundown
200
50841-09-19
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/5...
26
2
Train
Logged In
Ryan
M
2
Smith
205.45261
free
San Jose-Sunnyvale-Santa Clara, CA
PUT
NextSong
1.541017e+12
583
Marry Me
200
50841-09-22
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/5...
26
3
Sony Wonder
Logged In
Samuel
M
0
Gonzalez
218.06975
free
Houston-The Woodlands-Sugar Land, TX
PUT
NextSong
1.540493e+12
597
Blackbird
200
50842-01-24
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_4...
61
4
Van Halen
Logged In
Tegan
F
2
Levine
289.38404
paid
Portland-South Portland, ME
PUT
NextSong
1.540794e+12
602
Best Of Both Worlds (Remastered Album Version)
200
50842-04-21
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_4...
80
df_time = df_log.select('ts')
df_time.take(5)
[Row(ts=1542241826796),
Row(ts=1542242481796),
Row(ts=1542242741796),
Row(ts=1542253449796),
Row(ts=1542260935796)]
@udf
def gettimestamp(time):
import datetime
time = time/1000
return datetime.datetime.fromtimestamp(time).strftime("%m-%d-%Y %H:%M:%S")
df_time.withColumn("timestamp", gettimestamp("ts")).show()
+-------------+-------------------+
| ts| timestamp|
+-------------+-------------------+
|1542241826796|11-15-2018 00:30:26|
|1542242481796|11-15-2018 00:41:21|
|1542242741796|11-15-2018 00:45:41|
|1542253449796|11-15-2018 03:44:09|
|1542260935796|11-15-2018 05:48:55|
|1542261224796|11-15-2018 05:53:44|
|1542261356796|11-15-2018 05:55:56|
|1542261662796|11-15-2018 06:01:02|
|1542262057796|11-15-2018 06:07:37|
|1542262233796|11-15-2018 06:10:33|
|1542262434796|11-15-2018 06:13:54|
|1542262456796|11-15-2018 06:14:16|
|1542262679796|11-15-2018 06:17:59|
|1542262728796|11-15-2018 06:18:48|
|1542262893796|11-15-2018 06:21:33|
|1542263158796|11-15-2018 06:25:58|
|1542263378796|11-15-2018 06:29:38|
|1542265716796|11-15-2018 07:08:36|
|1542265929796|11-15-2018 07:12:09|
|1542266927796|11-15-2018 07:28:47|
+-------------+-------------------+
only showing top 20 rows
df_time.printSchema()
root
|-- ts: long (nullable = true)
get_timestamp = F.udf(lambda x: datetime.fromtimestamp( (x/1000.0) ), T.TimestampType())
get_hour = F.udf(lambda x: x.hour, T.IntegerType())
get_day = F.udf(lambda x: x.day, T.IntegerType())
get_week = F.udf(lambda x: x.isocalendar()[1], T.IntegerType())
get_month = F.udf(lambda x: x.month, T.IntegerType())
get_year = F.udf(lambda x: x.year, T.IntegerType())
get_weekday = F.udf(lambda x: x.weekday(), T.IntegerType())
df_log = df_log.withColumn("timestamp", get_timestamp(df_log.ts))
df_log = df_log.withColumn("hour", get_hour(df_log.timestamp))
df_log = df_log.withColumn("day", get_day(df_log.timestamp))
df_log = df_log.withColumn("week", get_week(df_log.timestamp))
df_log = df_log.withColumn("month", get_month(df_log.timestamp))
df_log = df_log.withColumn("year", get_year(df_log.timestamp))
df_log = df_log.withColumn("weekday", get_weekday(df_log.timestamp))
df_log.limit(5).toPandas()
artist
auth
firstName
gender
itemInSession
lastName
length
level
location
method
...
ts
userAgent
userId
timestamp
hour
day
week
month
year
weekday
0
Harmonia
Logged In
Ryan
M
0
Smith
655.77751
free
San Jose-Sunnyvale-Santa Clara, CA
PUT
...
1542241826796
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/5...
26
2018-11-15 00:30:26.796
0
15
46
11
2018
3
1
The Prodigy
Logged In
Ryan
M
1
Smith
260.07465
free
San Jose-Sunnyvale-Santa Clara, CA
PUT
...
1542242481796
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/5...
26
2018-11-15 00:41:21.796
0
15
46
11
2018
3
2
Train
Logged In
Ryan
M
2
Smith
205.45261
free
San Jose-Sunnyvale-Santa Clara, CA
PUT
...
1542242741796
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/5...
26
2018-11-15 00:45:41.796
0
15
46
11
2018
3
3
Sony Wonder
Logged In
Samuel
M
0
Gonzalez
218.06975
free
Houston-The Woodlands-Sugar Land, TX
PUT
...
1542253449796
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_4...
61
2018-11-15 03:44:09.796
3
15
46
11
2018
3
4
Van Halen
Logged In
Tegan
F
2
Levine
289.38404
paid
Portland-South Portland, ME
PUT
...
1542260935796
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_4...
80
2018-11-15 05:48:55.796
5
15
46
11
2018
3
5 rows × 25 columns
time_cols = ["timestamp", "hour", "day", "week", "month", "year", "weekday"]
time_table_df = df_log.select(time_cols)
# write to parquet file partition by
time_table_df.write.parquet('data/time_table', partitionBy=['year', 'month'], mode='Overwrite')
# write this to s3 bucket
time_table_df.write.parquet(output + 'time_table', partitionBy=['year', 'month'], mode='Overwrite')
SongPlay table
df_log.printSchema()
root
|-- artist: string (nullable = true)
|-- auth: string (nullable = true)
|-- firstName: string (nullable = true)
|-- gender: string (nullable = true)
|-- itemInSession: long (nullable = true)
|-- lastName: string (nullable = true)
|-- length: double (nullable = true)
|-- level: string (nullable = true)
|-- location: string (nullable = true)
|-- method: string (nullable = true)
|-- page: string (nullable = true)
|-- registration: double (nullable = true)
|-- sessionId: long (nullable = true)
|-- song: string (nullable = true)
|-- status: long (nullable = true)
|-- ts: long (nullable = true)
|-- userAgent: string (nullable = true)
|-- userId: string (nullable = true)
|-- timestamp: timestamp (nullable = true)
|-- hour: integer (nullable = true)
|-- day: integer (nullable = true)
|-- week: integer (nullable = true)
|-- month: integer (nullable = true)
|-- year: integer (nullable = true)
|-- weekday: integer (nullable = true)
songplay_cols_temp = ["timestamp", "userId", "sessionId", "location", "userAgent", "level"]
df_log.select(songplay_cols).toPandas().head()
timestamp
userId
sessionId
location
userAgent
level
0
2018-11-15 00:30:26.796
26
583
San Jose-Sunnyvale-Santa Clara, CA
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/5...
free
1
2018-11-15 00:41:21.796
26
583
San Jose-Sunnyvale-Santa Clara, CA
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/5...
free
2
2018-11-15 00:45:41.796
26
583
San Jose-Sunnyvale-Santa Clara, CA
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/5...
free
3
2018-11-15 03:44:09.796
61
597
Houston-The Woodlands-Sugar Land, TX
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_4...
free
4
2018-11-15 05:48:55.796
80
602
Portland-South Portland, ME
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_4...
paid
# read the partitioned data
df_artists_read = spark.read.option("mergeSchema", "true").parquet("data/artists_table")
df_songs_read = spark.read.option("mergeSchema", "true").parquet("data/songs_table")
df_artists_read.toPandas().head()
artist_id
artist_name
artist_location
artist_latitude
artist_longitude
0
ARDR4AC1187FB371A1
Montserrat Caballé;Placido Domingo;Vicente Sar...
NaN
NaN
1
AREBBGV1187FB523D2
Mike Jones (Featuring CJ_ Mello & Lil' Bran)
Houston, TX
NaN
NaN
2
ARMAC4T1187FB3FA4C
The Dillinger Escape Plan
Morris Plains, NJ
40.82624
-74.47995
3
ARPBNLO1187FB3D52F
Tiny Tim
New York, NY
40.71455
-74.00712
4
ARDNS031187B9924F0
Tim Wilson
Georgia
32.67828
-83.22295
df_songs_read.toPandas().head()
song_id
title
duration
year
artist_id
0
SOAOIBZ12AB01815BE
I Hold Your Hand In Mine [Live At Royal Albert...
43.36281
2000
ARPBNLO1187FB3D52F
1
SONYPOM12A8C13B2D7
I Think My Wife Is Running Around On Me (Taco ...
186.48771
2005
ARDNS031187B9924F0
2
SODREIN12A58A7F2E5
A Whiter Shade Of Pale (Live @ Fillmore West)
326.00771
0
ARLTWXK1187FB5A3F8
3
SOYMRWW12A6D4FAB14
The Moon And I (Ordinary Day Album Version)
267.70240
0
ARKFYS91187B98E58F
4
SOWQTQZ12A58A7B63E
Streets On Fire (Explicit Album Version)
279.97995
0
ARPFHN61187FB575F6
# merge song and artists
df_songs_read.join(df_artists_read, 'artist_id').toPandas().head()
artist_id
song_id
title
duration
year
artist_name
artist_location
artist_latitude
artist_longitude
0
ARPBNLO1187FB3D52F
SOAOIBZ12AB01815BE
I Hold Your Hand In Mine [Live At Royal Albert...
43.36281
2000
Tiny Tim
New York, NY
40.71455
-74.00712
1
ARDNS031187B9924F0
SONYPOM12A8C13B2D7
I Think My Wife Is Running Around On Me (Taco ...
186.48771
2005
Tim Wilson
Georgia
32.67828
-83.22295
2
ARLTWXK1187FB5A3F8
SODREIN12A58A7F2E5
A Whiter Shade Of Pale (Live @ Fillmore West)
326.00771
0
King Curtis
Fort Worth, TX
32.74863
-97.32925
3
ARKFYS91187B98E58F
SOYMRWW12A6D4FAB14
The Moon And I (Ordinary Day Album Version)
267.70240
0
Jeff And Sheri Easter
NaN
NaN
4
ARPFHN61187FB575F6
SOWQTQZ12A58A7B63E
Streets On Fire (Explicit Album Version)
279.97995
0
Lupe Fiasco
Chicago, IL
41.88415
-87.63241
df_joined_songs_artists = df_songs_read.join(df_artists_read, 'artist_id').select("artist_id", "song_id", "title", "artist_name")
songplay_cols = ["timestamp", "userId", "song_id", "artist_id", "sessionId", "location", "userAgent", "level", "month", "year"]
# join df_logs with df_joined_songs_artists
df_log.join(df_joined_songs_artists, df_log.artist == df_joined_songs_artists.artist_name).select(songplay_cols).toPandas().head()
timestamp
userId
song_id
artist_id
sessionId
location
userAgent
level
month
year
0
2018-11-10 07:47:51.796
44
SOWQTQZ12A58A7B63E
ARPFHN61187FB575F6
350
Waterloo-Cedar Falls, IA
Mozilla/5.0 (Macintosh; Intel Mac OS X 10.9; r...
paid
11
2018
1
2018-11-06 18:34:31.796
97
SOWQTQZ12A58A7B63E
ARPFHN61187FB575F6
293
Lansing-East Lansing, MI
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/5...
paid
11
2018
2
2018-11-06 16:04:44.796
2
SOWQTQZ12A58A7B63E
ARPFHN61187FB575F6
126
Plymouth, IN
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebK...
free
11
2018
3
2018-11-28 23:22:57.796
24
SOWQTQZ12A58A7B63E
ARPFHN61187FB575F6
984
Lake Havasu City-Kingman, AZ
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebK...
paid
11
2018
4
2018-11-14 13:11:26.796
34
SOWQTQZ12A58A7B63E
ARPFHN61187FB575F6
495
Milwaukee-Waukesha-West Allis, WI
Mozilla/5.0 (Macintosh; Intel Mac OS X 10.9; r...
free
11
2018
songplay_table_df = df_log.join(df_joined_songs_artists, df_log.artist == df_joined_songs_artists.artist_name).select(songplay_cols)
songplay_table_df = songplay_table_df.withColumn("songplay_id", F.monotonically_increasing_id())
songplay_table_df.toPandas().head()
timestamp
userId
song_id
artist_id
sessionId
location
userAgent
level
month
year
songplay_id
0
2018-11-10 07:47:51.796
44
SOWQTQZ12A58A7B63E
ARPFHN61187FB575F6
350
Waterloo-Cedar Falls, IA
Mozilla/5.0 (Macintosh; Intel Mac OS X 10.9; r...
paid
11
2018
0
1
2018-11-06 18:34:31.796
97
SOWQTQZ12A58A7B63E
ARPFHN61187FB575F6
293
Lansing-East Lansing, MI
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/5...
paid
11
2018
1
2
2018-11-06 16:04:44.796
2
SOWQTQZ12A58A7B63E
ARPFHN61187FB575F6
126
Plymouth, IN
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebK...
free
11
2018
2
3
2018-11-28 23:22:57.796
24
SOWQTQZ12A58A7B63E
ARPFHN61187FB575F6
984
Lake Havasu City-Kingman, AZ
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebK...
paid
11
2018
3
4
2018-11-14 13:11:26.796
34
SOWQTQZ12A58A7B63E
ARPFHN61187FB575F6
495
Milwaukee-Waukesha-West Allis, WI
Mozilla/5.0 (Macintosh; Intel Mac OS X 10.9; r...
free
11
2018
4
# write this to parquet file
# write to parquet file partition by
songplay_table_df.write.parquet('data/songplays_table', partitionBy=['year', 'month'], mode='Overwrite')
from pyspark.sql import functions as F
from glob import glob
test_df = spark.read.json(glob("test/*.json"))
test_df.select(['song_id', 'title', 'artist_id', 'year', 'duration']).toPandas()
song_id
title
artist_id
year
duration
0
SOYMRWW12A6D4FAB14
The Moon And I (Ordinary Day Album Version)
ARKFYS91187B98E58F
0
267.70240
1
SOHKNRJ12A6701D1F8
Drop of Rain
AR10USD1187B99F3F1
0
189.57016
2
SOYMRWW12A6D4FAB14
The Moon And SUN
ASKFYS91187B98E58F
0
269.70240
3
SOUDSGM12AC9618304
Insatiable (Instrumental Version)
ARNTLGG11E2835DDB9
0
266.39628
test_df.select(['song_id', 'title', 'artist_id', 'year', 'duration']).groupBy('song_id').count().show()
+------------------+-----+
| song_id|count|
+------------------+-----+
|SOUDSGM12AC9618304| 1|
|SOYMRWW12A6D4FAB14| 2|
|SOHKNRJ12A6701D1F8| 1|
+------------------+-----+
test_df.select(F.col('song_id'), 'title') \
.groupBy('song_id') \
.agg({'title': 'first'}) \
.withColumnRenamed('first(title)', 'title1') \
.show()
+------------------+--------------------+
| song_id| title|
+------------------+--------------------+
|SOUDSGM12AC9618304|Insatiable (Instr...|
|SOYMRWW12A6D4FAB14|The Moon And I (O...|
|SOHKNRJ12A6701D1F8| Drop of Rain|
+------------------+--------------------+
t1 = test_df.select(F.col('song_id'), 'title') \
.groupBy('song_id') \
.agg({'title': 'first'}) \
.withColumnRenamed('first(title)', 'title1')
t2 = test_df.select(['song_id', 'title', 'artist_id', 'year', 'duration'])
t1.join(t2, 'song_id').where(F.col("title1") == F.col("title")).select(["song_id", "title", "artist_id", "year", "duration"]).show()
+------------------+--------------------+------------------+----+---------+
| song_id| title| artist_id|year| duration|
+------------------+--------------------+------------------+----+---------+
|SOYMRWW12A6D4FAB14|The Moon And I (O...|ARKFYS91187B98E58F| 0| 267.7024|
|SOHKNRJ12A6701D1F8| Drop of Rain|AR10USD1187B99F3F1| 0|189.57016|
|SOUDSGM12AC9618304|Insatiable (Instr...|ARNTLGG11E2835DDB9| 0|266.39628|
+------------------+--------------------+------------------+----+---------+